目的:
在上一篇,我們使用Python來學習爬蟲這玩意,今天,我們就來做一個微進階吧 ! 今天我們來學習,如何從 指定網頁來下載圖片 ( 男人… 你懂得 )
源碼:
在上一篇,我們使用Python來學習爬蟲這玩意,今天,我們就來做一個微進階吧 ! 今天我們來學習,如何從 指定網頁來下載圖片 ( 男人… 你懂得 )
源碼:
import requests import urllib.request from bs4 import BeautifulSoup import os import time url = 'https://www.google.com/search?q=%E7%BE%8E%E5%A5%B3&rlz=1C2CAFB_enTW617TW617&source=lnms&tbm=isch&sa=X&ved=0ahUKEwictOnTmYDcAhXGV7wKHX-OApwQ_AUICigB&biw=1128&bih=960' photolimit = 10 headers = {'User-Agent': 'Mozilla/5.0'} response = requests.get(url,headers = headers) #使用header避免訪問受到限制 soup = BeautifulSoup(response.content, 'html.parser') items = soup.find_all('img') folder_path ='./photo/' if (os.path.exists(folder_path) == False): #判斷資料夾是否存在 os.makedirs(folder_path) #Create folder for index , item in enumerate (items): if (item and index < photolimit ): html = requests.get(item.get('src')) # use 'get' to get photo link path , requests = send request img_name = folder_path + str(index + 1) + '.png' with open(img_name,'wb') as file: #以byte的形式將圖片數據寫入 file.write(html.content) file.flush() file.close() #close file print('第 %d 張' % (index + 1)) time.sleep(1) print('Done')
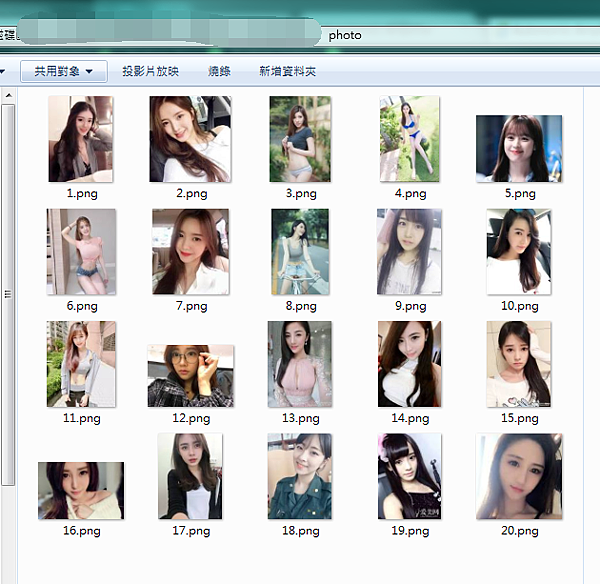
進階使用 :
其實也沒啥特別的,就是加上一個關鍵字搜尋而已 ( 感覺就更不同了 )
word = input('Input key word: ') url = 'https://www.google.com.tw/search?q='+word+' &rlz=1C1CAFB_enTW617TW621&source=lnms&tbm=isch&sa=X&ved=0ahUKEwienc6V1oLcAhVN-WEKHdD_B3EQ_AUICigB&biw=1128&bih=863'
我們將url的撰寫方式改變一下,找到google搜尋關鍵字的方式,將那邊的字替換掉,就可以囉。

至於有多正 ... 嘿嘿 各位老司機們,就自己去發現囉。
文章標籤
全站熱搜

 留言列表
留言列表
 {{ article.title }}
{{ article.title }}